
背景
借助 Foundation Models 框架,开发者不仅可以通过简洁直观的 API 调用完成文本生成、对话管理、结构化数据输出等任务,还可以结合 Swift 的类型安全机制与 @Generable 宏定义强约束的数据模型,实现与传统编程范式高度一致的模型交互体验。与此同时,Tool Calling、Snapshot Streaming、Dynamic Generation Schema 等机制也为构建 AI 原生应用提供了丰富的能力扩展手段。
需要说明的是,截至目前,Apple Intelligence 尚未在中国大陆正式推出,国行设备用户暂无法体验 Foundation Model 的实际功能。因此,本文不会涉及该模型的开发实操与使用体验,而是聚焦于另一个核心议题: 苹果究竟是如何对LLM进行合理且高效的封装设计*。
以下 Demo 代码来自 Apple官方文档。
截止目前 Apple Intelligence 尚未在中国大陆正式推出,如果你购买的设备是国行的那更是遥遥无期了。所以本文并不会讨论 Foundation Model 实际的开发和使用体验, 本分享主要探讨的是 Apple 如何实现一个合理的封装。
前言:传统封装
在传统方式下,Swift / Objective-C 调用大语言模型 API 主要依赖手动封装 HTTP 请求,常见的接入对象包括 OpenAI、Anthropic 等厂商或云服务商提供的 RESTful 接口。目前,这些服务普遍尚未提供官方的 Swift SDK。以 OpenAI 的 Chat Completions API 为例,开发者通常需要自行定义请求与响应的数据模型,并通过 URLSession 等方式构造网络请求来完成调用。
import Foundation
struct OpenAIRequest: Codable {
let model: String
let messages: [Message]
}
struct Message: Codable {
let role: String
let content: String
}
struct OpenAIResponse: Codable {
struct Choice: Codable {
let message: Message
}
let choices: [Choice]
}
func callOpenAI(prompt: String) async throws -> String {
let apiKey = "<YOUR_API_KEY>"
let url = URL(string: "https://api.openai.com/v1/chat/completions")!
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.addValue("Bearer (apiKey)", forHTTPHeaderField: "Authorization")
request.addValue("application/json", forHTTPHeaderField: "Content-Type")
let requestBody = OpenAIRequest(
model: "gpt-4",
messages: [Message(role: "user", content: prompt)]
)
request.httpBody = try JSONEncoder().encode(requestBody)
let (data, _) = try await URLSession.shared.data(for: request)
let result = try JSONDecoder().decode(OpenAIResponse.self, from: data)
return result.choices.first?.message.content ?? ""
}
Task {
let reply = try await callOpenAI(prompt: "用一句话解释量子纠缠")
print(reply)
}显然以上裸调用的方式不太符合工程学实践,作为一个软件工程师,你大概率会将上面的逻辑封装成 Service 类或是一个模块。
class OpenAIService {
static let shared = OpenAIService(apiKey: "<key>")
private let apiKey: String
init(apiKey: String) {
self.apiKey = apiKey
}
func chat(prompt: String) async throws -> String {
// 和上面类似的实现
}
}这种方式虽然方便复用,但仍然没有脱离“JSON 结构定义 + RESTful API 调用 + 手动管理 HTTP 请求”的范式。程序员都喜欢造轮子,开发者们创建了很多针对 Chat Completions API 的 Swift 封装库,例如这个在 GitHub 上有 1.7K Star 的 OpenAISwift,README中作者给出了具体的调用用例:
import OpenAISwift
let openAI = OpenAISwift(config: OpenAISwift.Config.makeDefaultOpenAI(apiKey: MY SECRET KEY))
openAI.sendCompletion(with: "Hello how are you") { result in // Result<OpenAI, OpenAIError>
switch result {
case .success(let success):
print(success.choices.first?.text ?? "")
case .failure(let failure):
print(failure.localizedDescription)
}
}
do {
let chat: [ChatMessage] = [
ChatMessage(role: .system, content: "You are a helpful assistant."),
ChatMessage(role: .user, content: "Who won the world series in 2020?"),
ChatMessage(role: .assistant, content: "The Los Angeles Dodgers won the World Series in 2020."),
ChatMessage(role: .user, content: "Where was it played?")
]
let result = try await openAI.sendChat(
with: chat,
model: .chat(.chatgpt), // optional `OpenAIModelType`
user: nil, // optional `String?`
temperature: 1, // optional `Double?`
topProbabilityMass: 1, // optional `Double?`
choices: 1, // optional `Int?`
stop: nil, // optional `[String]?`
maxTokens: nil, // optional `Int?`
presencePenalty: nil, // optional `Double?`
frequencyPenalty: nil, // optional `Double?`
logitBias: nil // optional `[Int: Double]?` (see inline documentation)
)
// use result
} catch {
// ...
}总的来说,开发者使用上述的方式可以灵活实现服务端 LLM 的调用,但对开发者来说,除了需要负担一些经济成本,并且需要保证对话联网,即无法享受本地推理、隐私保障等体验。
如果不想要使用服务端LLM,目前也有一些方案提供了调用本地LLM的能力,例如 LLM.swift 就提供了一套调用本地 LLM 的能力。
let systemPrompt = "You are a sentient AI with emotions."
let bot = await LLM(from: HuggingFaceModel("unsloth/Qwen3-0.6B-GGUF", .Q4_K_M, template: .chatML(systemPrompt)))!
let question = bot.preprocess("What's the meaning of life?", [])
let answer = await bot.getCompletion(from: question)
print(answer)使用本地 LLM 确实可以省略“手动管理 HTTP 请求和 API Key”的繁复,相较之下也更有安全性和经济性。然而在 Apple 看来这么做仍然不够优雅,理想的方案是将提示词工程的概念与客户端封装相结合。如果你没有看过《Prompt Engineering》白皮书 可以先移步了解一下提示词工程,这会对于你了解后面的内容有极大的帮助。
在我看来,Apple Foundation Models 代表了一种 系统级 AI 接口设计模式的转变:从调用“某个模型”,过渡为调用“完成某种任务”的 API。这种变化对 Swift 开发者尤其友好。接下来我们就看看 Apple 是怎么做的。
Stateful Session
为了支持多轮对话和保持上下文连贯性,Foundation Model 框架提供了 LanguageModelSession 这个有状态的会话对象,提供了
instructions:一组开发者设定的静态“系统指令”,用于指导模型总体行为,优先于用户 promptprompt: 用户向模型发出的输入请求,类似用户的一句话或任务指令。被用作respond(to:)的输入参数transcript: 记录整个对话历史(包括 Prompt 和响应)的数据结构, 开发者可用于调试、重用上下文或多轮对话展示
let session = LanguageModelSession(instructions: "You are a poet.")
let response1 = try await session.respond(to: "Describe the sea.")
let response2 = try await session.respond(to: "And now describe the sky.")例如在这个过程中, instructions 是 “You are a poet.”,第一条 Prompt 是“Describe the sea.”,第二条 Prompt 是“And now describe the sky.”,transcript是 Prompt 1 + Response 1 + Prompt 2 + Response 2。
LanguageModelSession 的这种封装方式使得开发者无需手动管理复杂的对话状态,简化了构建智能对话应用的难度,模型也能够基于完整的对话历史进行推理。具体来说有以下几个特点。
维护对话历史
会话对象会自动记录每次交互的 Prompt 和模型响应,使得模型能够“记住”之前的对话内容。即每次调用 respond(to:)方法都会记录完整的交互历史,并纳入上下文计算。
let options = GenerationOptions(temperature: 2.0)
let session = LanguageModelSession(instructions: """
You are a motivational workout coach that provides quotes to inspire \
and motivate athletes.
"""
)
let prompt = "Generate a motivational quote for my next workout."
let response = try await session.respond(
to: prompt,
options: options
)上下文管理
会话自动维护 transcript,包括初始 instructions ,以及所有用户和模型之间的消息。如果超出上下文限制,开发者可以捕获到类似 exceededContextWindowSize 的错误,自行选择重新开一个新 session 或是从 transcript 中保留核心条目(如 instructions + 最近回复)来构建新的 session。
// Option 1
var session = LanguageModelSession()
do {
let answer = try await session.respond(to: prompt)
print(answer.content)
} catch LanguageModelSession.GenerationError.exceededContextWindowSize {
// New session, without any history from the previous session.
session = LanguageModelSession()
}
// Option 2
var session = LanguageModelSession()
do {
let answer = try await session.respond(to: prompt)
print(answer.content)
} catch LanguageModelSession.GenerationError.exceededContextWindowSize {
// New session, with some history from the previous session.
session = newSession(previousSession: session)
}
private func newSession(previousSession: LanguageModelSession) -> LanguageModelSession {
let allEntries = previousSession.transcript.entries
var condensedEntries = [Transcript.Entry]()
if let firstEntry = allEntries.first {
condensedEntries.append(firstEntry)
if allEntries.count > 1, let lastEntry = allEntries.last {
condensedEntries.append(lastEntry)
}
}
let condensedTranscript = Transcript(entries: condensedEntries)
// Note: transcript includes instructions.
return LanguageModelSession(transcript: condensedTranscript)
}控制会话行为
开发者可以通过 GenerationOptions 等参数,对会话中的模型行为进行细粒度控制,例如设置temperature、sampling、maximumResponseTokens。
// Deterministic output
let response = try await session.respond(
to: prompt,
options: GenerationOptions(sampling: .greedy)
)
// Low-variance output
let response = try await session.respond(
to: prompt,
options: GenerationOptions(temperature: 0.5)
)
// High-variance output
let response = try await session.respond(
to: prompt,
options: GenerationOptions(temperature: 2.0)
)时序管理
会话对象一次只能处理一个请求,如果在上一个请求完成之前再次调用则会导致 runtime 错误,开发者需要主动判断 isResponding状态来验证会话是否已完成处理上一个请求,然后再发送新请求。也可以同时创建多个会话对象。
Foundation Model 在框架层面保证了流式输出期间 session.isResponding = true,可避免重复提交 prompt。
import SwiftUI
import FoundationModels
struct HaikuView: View {
@State private var session = LanguageModelSession()
@State private var haiku: String?
var body: some View {
if let haiku {
Text(haiku)
}
Button("Go!") {
Task {
haiku = try await session.respond(
to: "Write a haiku about something you haven't yet"
).content
}
}
// 根据 isResponding 禁用按钮
.disabled(session.isResponding)
}
}适配器
除了默认的通用模型,框架还提供了内置的专用用例(如内容标签、实体抽取等),通过适配器(adapter)实现。可在初始化时指定:
let session = LanguageModelSession(
model: SystemLanguageModel(useCase: .contentTagging)
)以下为 Apple 在 Foundation Model 框架中提供的内建任务适配器,它们封装了特定用途的 Prompt 模板和参数,开发者可以直接调用用于不同的智能任务。
| Adapter 名称 | 功能说明 |
|---|---|
contentTagging | 对文本或图像内容打标签,提取关键词、实体、情感等。常用于内容分类、搜索增强。 |
summarization | 将长文本压缩为简洁摘要,支持新闻、邮件、会议记录等场景。 |
translation | 支持多语言文本互译,覆盖英文、中文、法语、西班牙语等主流语言对。 |
textToImage | 根据文本描述生成图像,适用于插画生成、创意设计等。 |
imageCaptioning | 给图片生成描述性文字,用于辅助理解图像内容或生成 alt 文本。 |
sentimentAnalysis | 分析文本的情绪倾向,如积极、中性、消极等,用于评论分析、用户反馈等。 |
entityExtraction | 从文本中提取人名、地名、组织等命名实体,可用于结构化信息提取。 |
textRewriting | 改写原始文本,可用于语气调整、语言润色、简化或复杂化表达等。 |
codeCompletion | 提供代码补全建议,当前支持 Swift、Python 等语言。 |
grammarCorrection | 识别并纠正文本中的拼写和语法错误,用于输入优化和教育场景。 |
questionAnswering | 基于上下文内容回答具体问题,常用于搜索引擎、聊天机器人、RAG 系统等。 |
Guided Generation
@Generable
传统上,大语言模型的输出通常是自由形式的文本,这给开发者带来了挑战,包括如何从非结构化的文本中准确地提取所需信息,以及如何确保模型输出符合预期的格式。Foundation Model 通过引入 @Generable 宏解决了这一痛点。
@Generable 宏允许开发者将任何 Swift struct 或 class 标记为可生成类型,还可以进一步控制属性值,例如可以对 struct、actor 和 enum 使用 Generable(description:) ,可以对存储的属性使用 Guide(description:) 。当一个类型被标记为 @Generable 后,Foundation Model 框架会在编译时自动生成必要的代码,使得模型能够理解并严格按照该类型的定义来生成数据。
@Generable(description: "Basic profile information about a cat")
struct CatProfile {
// A guide isn't necessary for basic fields.
var name: String
@Guide(description: "The age of the cat", .range(0...20))
var age: Int
@Guide(description: "A one sentence profile about the cat's personality")
var profile: String
}
// Generate a response using a custom type.
let response = try await session.respond(
to: "Generate a cute rescue cat",
generating: CatProfile.self
)开发者可以像定义普通 Swift 数据模型一样定义结构化数据,并与LanguageModelSession 搭配完成生成任务。这种封装方式使得开发者可以直接操作 Swift 对象而不是解析字符串,从而避免了潜在的 runtime 错误和繁琐的字符串处理逻辑。
框架支持使用基本的 Swift 类型( 如 Bool、Int、Float、Double、Decimal 和 Array)生成内容,并且允许嵌套(自定义 Generable 类型嵌套在其他 Generable 类型中),简化了业务逻辑的开发。以下为 NatashaTheRobot 提供的Demo代码,开发者可以使用 Playground 直接看到生成的结果。
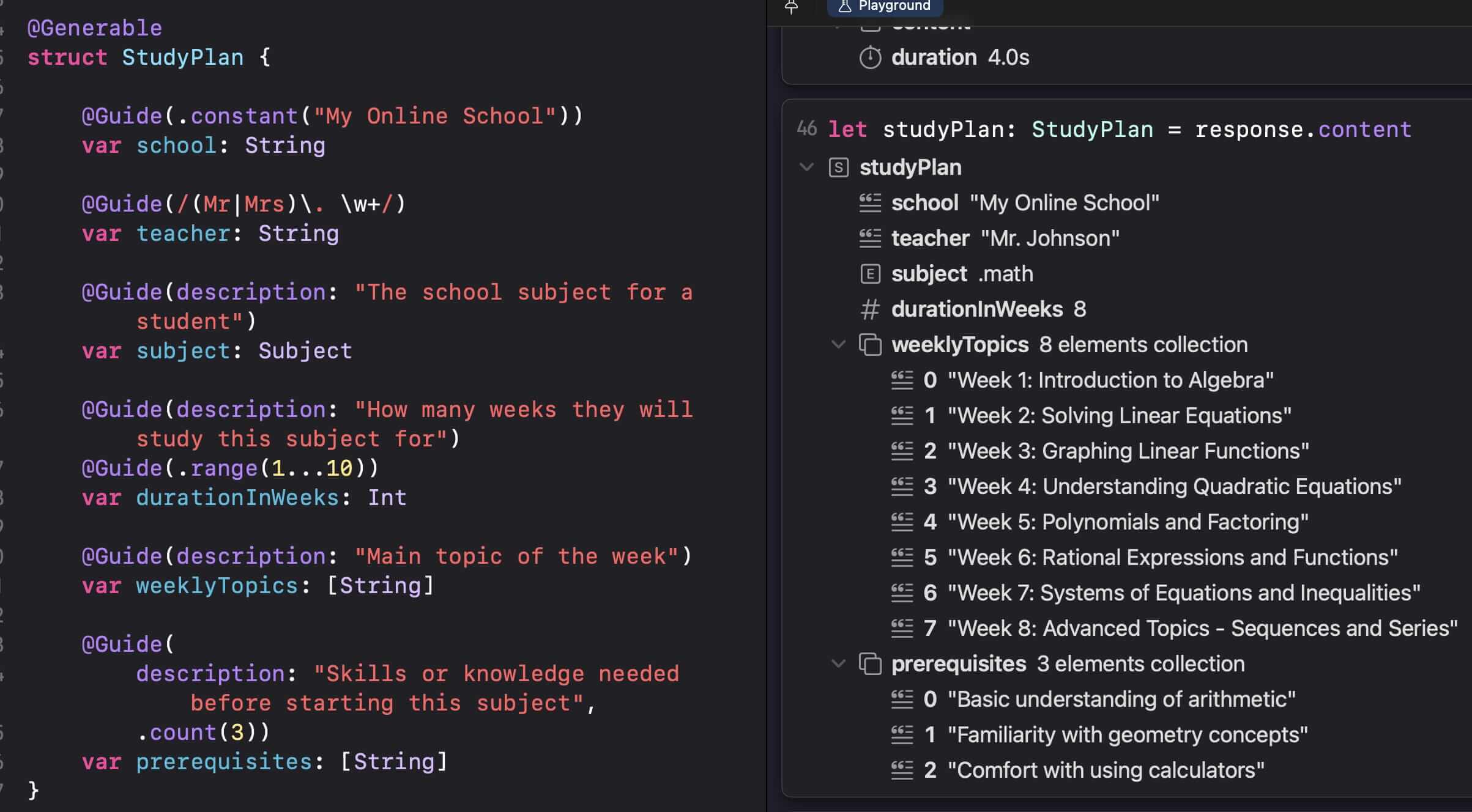
此外,Foundation Model 还支持通过 DynamicGenerationSchema 在运行时动态构建模型的输出格式,包括你希望生成的数据长什么样、字段有哪些、类型是什么、每个字段是否可选、字段之间有没有依赖关系等等,都可以以声明式方式在运行时定义结构。
DynamicGenerationSchema
DynamicGenerationSchema 与 Generable区别在于前者在运行时动态构建,适用于字段不确定、结构动态的case,而Generable在编译时以固定结构定义,适用于结构明确、字段已知的case。开发者可以根据不同的业务需求,灵活地调整模型输出的结构和约束。
let menuSchema = DynamicGenerationSchema(
name: "Menu",
properties: [
DynamicGenerationSchema.Property(
name: "dailySoup",
schema: DynamicGenerationSchema(
name: "dailySoup",
anyOf: ["Tomato", "Chicken Noodle", "Clam Chowder"]
)
)
// Add additional properties.
]
)
// Create the schema.
let schema = try GenerationSchema(root: menuSchema, dependencies: [])
// Pass the schema to the model to guide the output.
let response = try await session.respond(
to: "The prompt you want to make.",
schema: schema
)实现思路
第三方的 LLM.swift 也提供了类似的能力,在使用上相比 Apple 的实现还是缺失了一些灵活性,以下是它的@Generatable 使用方法。
@Generatable
enum Priority {
case low, medium, high, urgent
}
@Generatable
struct Address {
let street: String
let city: String
let zipCode: String
}
@Generatable
struct Task {
let title: String
let priority: Priority
let assignee: Person // Nested Generatable struct
}
@Generatable
struct Project {
let name: String
let tasks: [Task] // Arrays of Generatable structs
let teamLead: Person // Nested Generatable types
let office: Address // Multiple levels of nesting
}
let result = try await bot.respond(to: "Create a software project plan", as: Project.self)我们可以参考它的源代码归纳出一些实现思路,我们的目标很简单,即要求模型输出严格遵循结构定义(schema),以便自动解析为类型安全的 Swift 对象。
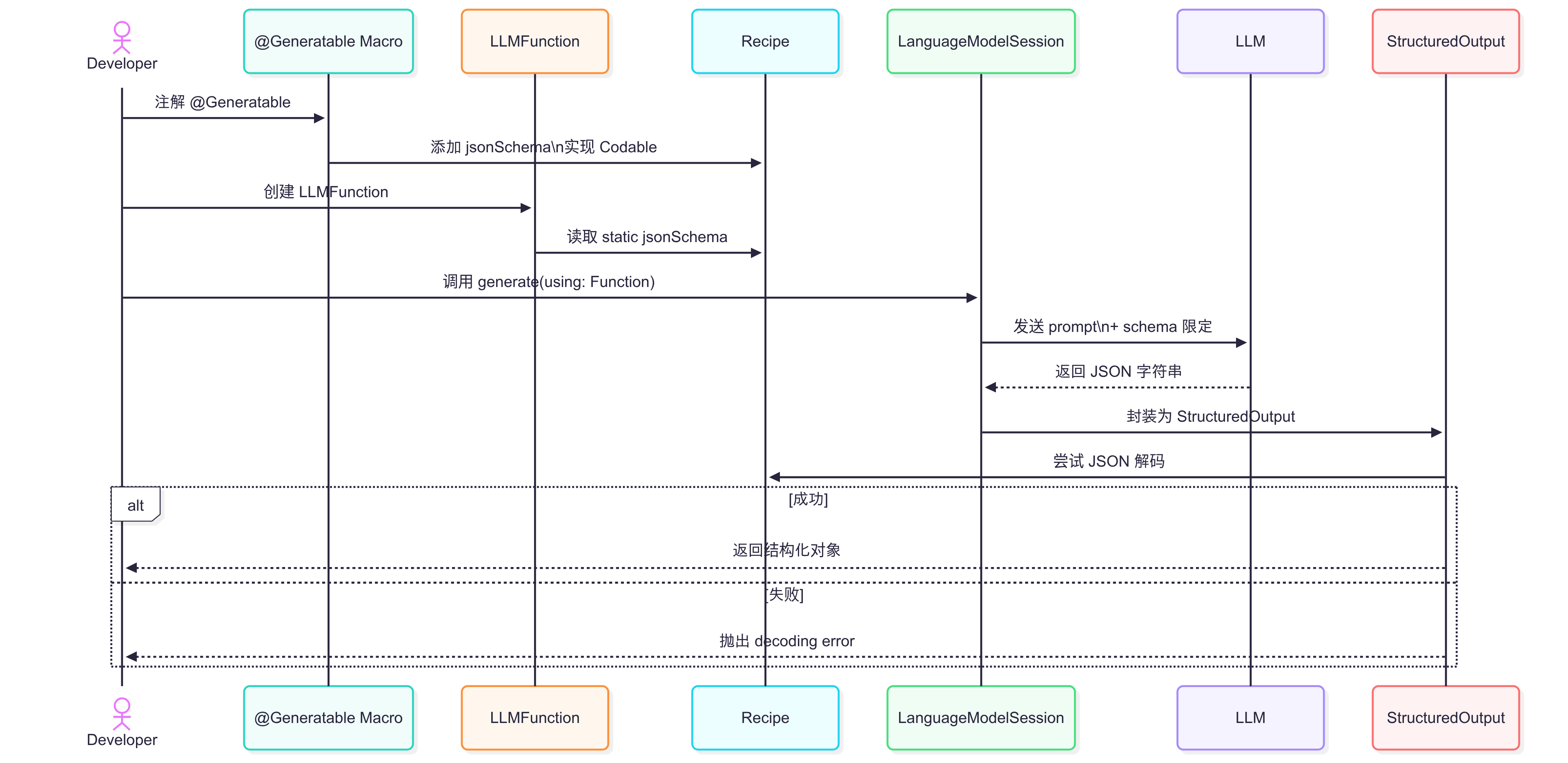
首先声明了一个Generatable protocol,要求类型必须符合 Codable(即支持编码/解码),必须提供一个 jsonSchema 静态属性用于描述该类型的 JSON 结构定义。
当一个类型(struct / enum)使用 @Generatable 宏时,自动插入以下成员函数:
jsonSchema:自动生成static var jsonSchema: Stringinit:合成一个默认构造器encode:合成一个编码方法(可能用于 JSON encoding)
自动为它添加协议遵循:
Codable: 确保符合序列化需求Generatable: 自己本身CaseIterable: 如果是 enum 类型,生成 .allCases 等功能(如果适用)
// Sources/LLMMacros/Generatable.swift
import SwiftSyntaxMacros
public protocol Generatable: Codable {
static var jsonSchema: String { get }
}
@attached(member, names: named(jsonSchema), named(init), named(encode))
@attached(extension, conformances: Codable, Generatable, CaseIterable)
public macro Generatable() = #externalMacro(module: "LLMMacrosImplementation", type: "GeneratableMacro")GeneratableMacro 的实现部分在 GeneratableMacro.swift,使用了 Swift 的 SwiftSyntaxMacros 来进行 结构化代码生成。以下是宏最核心的逻辑之一,即当类型使用了 @Generatable,这部分负责为其生成成员(目前是 jsonSchema)。
public static func expansion(
of node: AttributeSyntax,
providingMembersOf declaration: some DeclGroupSyntax,
conformingTo: [TypeSyntax],
in context: some MacroExpansionContext
) throws -> [DeclSyntax]我让GPT总结了这一段宏实现了什么,具体来说
- 为 struct 或 enum 添加
jsonSchema属性,自动生成 JSON Schema。 - 自动遵循
Codable,Generatable,CaseIterable(enum)。 - enum 会生成自定义的编码/解码方法。
- 自动分析成员属性类型,包括 Optional、Array、自定义类型,生成嵌套 schema。
- 减少样板代码,便于与 LLM、后端 schema、API toolchain 接轨。
对于下面的声明 User 和 Address,LLM.swift 会自动生成jsonSchema,简化了结构化 LLM 输出的声明和解析,避免手写 schema ,LLM 就能知道 name 是字符串、age 是整数(可选),并生成合法 JSON 响应。
@Generatable
struct User {
let name: String
let age: Int?
let tags: [String]
let address: Address
}
struct Address: Generatable {
let street: String
let zipCode: Int
}extension Address: Codable, Generatable {}
public static var jsonSchema: String {
return """
{ "type": "object", "properties": {
"street": { "type": "string" },
"zipCode": { "type": "integer" }
}, "required": ["street", "zipCode"] }
"""
}
extension User: Codable, Generatable {}
public static var jsonSchema: String {
return """
{ "type": "object", "properties": {
"name": { "type": "string" },
"age": { "type": "integer" },
"tags": { "type": "array", "items": { "type": "string" } },
"address": """ + Address.jsonSchema + """
}, "required": ["name", "tags", "address"] }
"""
}可以合理猜测,开发者在启动了 LanguageModelSession.generate(...)之后,session 将 prompt 和 schema 一起发送给LLM,LLM 返回的结构化输出由 CodableDecoder 解析为 Swift struct,进而开发者就可以拿到类型安全的结果。
Tool Calling
声明
Foundation Model 的另一个值得称道的封装在于其“工具调用”机制。Apple 的 Tool Calling 和 OpenAI 的 Tool Calling 都是让大模型在对话中自动调用开发者提供的函数以完成任务的机制。OpenAI 的方式基于 JSON Schema,通过结构化描述函数接口,支持模型自动判断是否调用、生成参数并执行,适用于多语言、多平台的云端服务场景;而 Apple 的 Tool Calling 更偏向本地端集成,结合 Guided Generation 实现更原生、更本地化的体验。
Tool 协议定义了一个标准接口,允许开发者将自定义的功能(如查询数据库、调用外部 API、执行设备功能等)暴露给 Foundation Model。
protocol Tool: Codable, Hashable {
var name: String { get }
var description: String { get }
func call(arguments: Arguments) async throws -> String
}当模型在处理用户请求时,它会根据当前上下文和用户意图,自主判断是否需要调用某个工具来获取信息或执行操作。如果模型决定调用工具,它会生成一个符合工具定义的参数列表,并由框架负责实际执行该工具。工具执行的结果会返回给模型,模型再根据结果生成最终的用户响应。
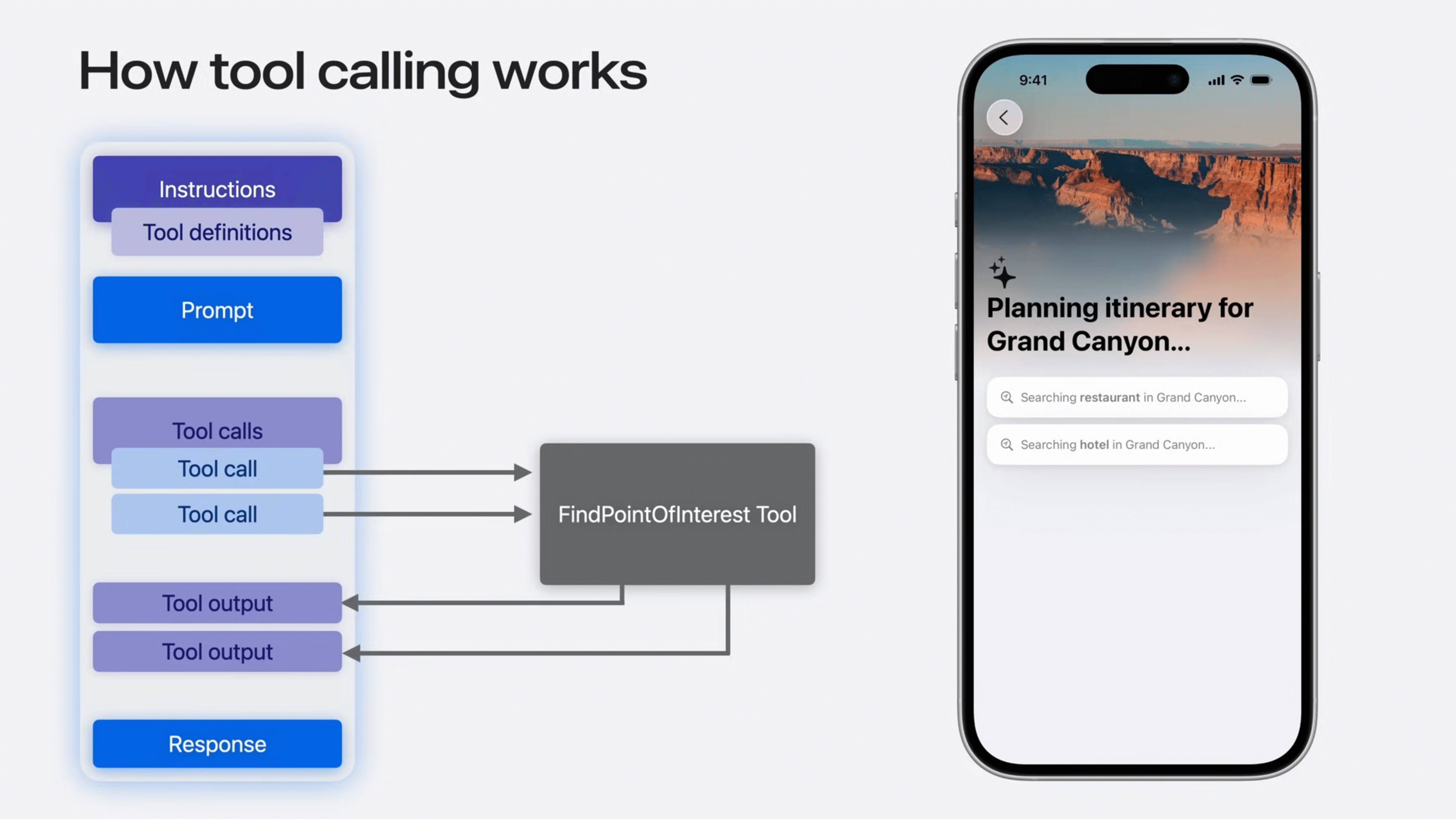
这种封装方式的特点在于:
-
能力扩展:模型不再局限于其内部知识,可以通过工具调用与外部系统进行交互,极大地扩展了其解决问题的能力。
-
模块化:开发者可以将复杂的功能封装成独立的工具,提高了代码的复用性和可维护性。
-
自主性:模型能够自主决定何时以及如何使用工具,降低了开发者在业务逻辑中显式调用工具的复杂性。
使用方法
一个旅行规划应用可以定义一个 FlightSearchTool用于查询航班信息;一个智能家居应用可以定义一个 LightControlTool用于控制智能灯光。模型可以根据用户的自然语言指令智能地调用这些工具来完成任务。
以下为 Apple 官方提供的GetWeatherTool代码样例,框架自动处理 “模型生成参数→调用call方法→获取天气结果→整合结果生成最终响应” 的流程。具体来说,当用户输入 “What is the temperature in Cupertino?” :
- 识别需调用
GetWeatherTool工具 - 生成
arguments - 执行
call方法得到输出 - 将输出回传给模型,生成该地区的天气描述
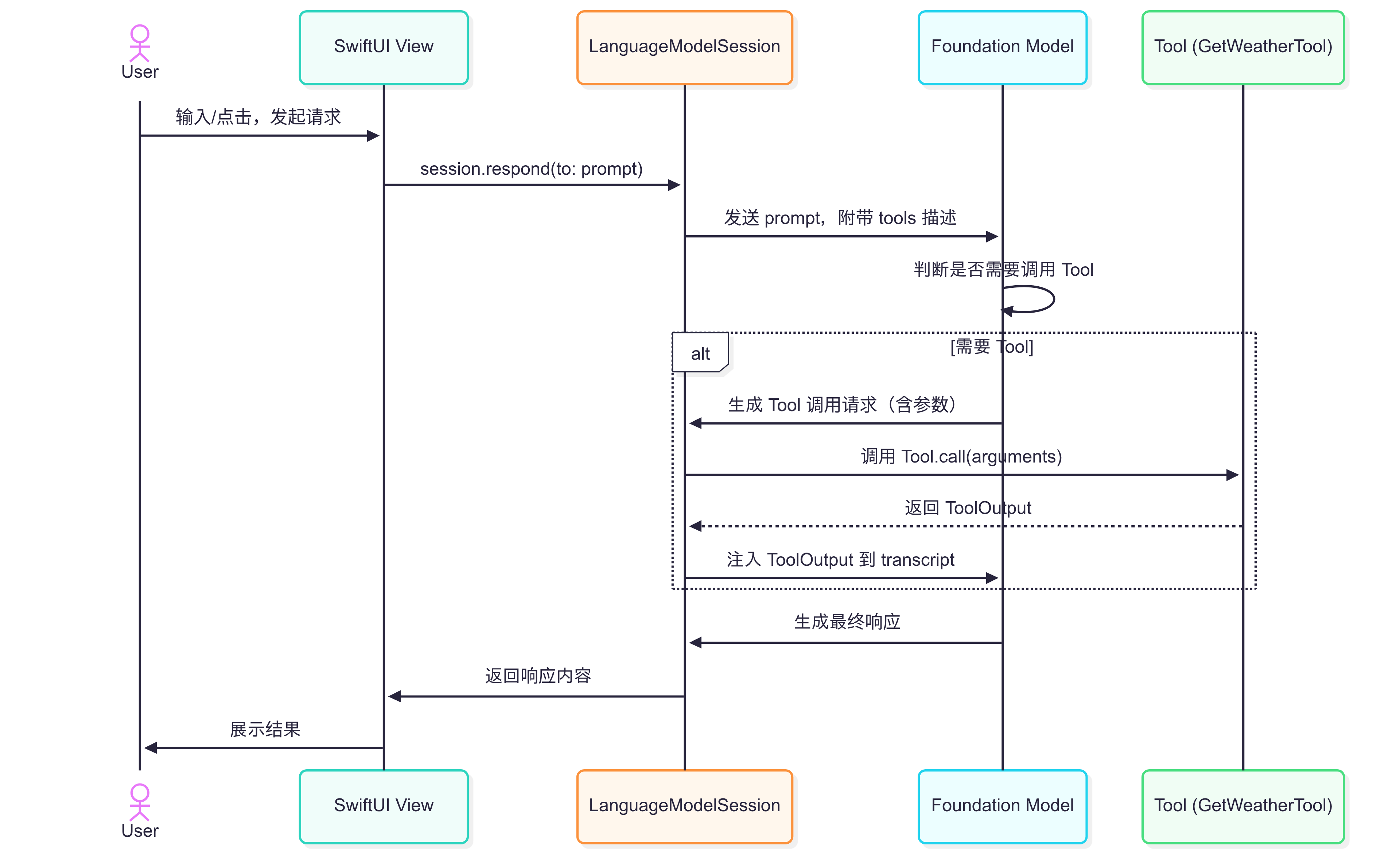
Tool 的输出可以是一个字符串,或一个 GeneratedContent 对象。模型可以并行多次调用工具来满足请求,例如检索多个城市的天气详情。
// Defining a tool
import WeatherKit
import CoreLocation
import FoundationModels
struct GetWeatherTool: Tool {
let name = "getWeather"
let description = "Retrieve the latest weather information for a city"
@Generable
struct Arguments {
@Guide(description: "The city to fetch the weather for")
var city: String
}
func call(arguments: Arguments) async throws -> ToolOutput {
let places = try await CLGeocoder().geocodeAddressString(arguments.city)
let weather = try await WeatherService.shared.weather(for: places.first!.location!)
let temperature = weather.currentWeather.temperature.value
let content = GeneratedContent(properties: ["temperature": temperature])
let output = ToolOutput(content)
// Or if your tool’s output is natural language:
// let output = ToolOutput("(arguments.city)'s temperature is (temperature) degrees.")
return output
}
}
// Attaching tools to a session
let session = LanguageModelSession(
tools: [GetWeatherTool()],
instructions: "Help the user with weather forecasts."
)
let response = try await session.respond(
to: "What is the temperature in Cupertino?"
)
print(response.content)
// It’s 71˚F in Cupertino!Snapshot Streaming
streamResponse
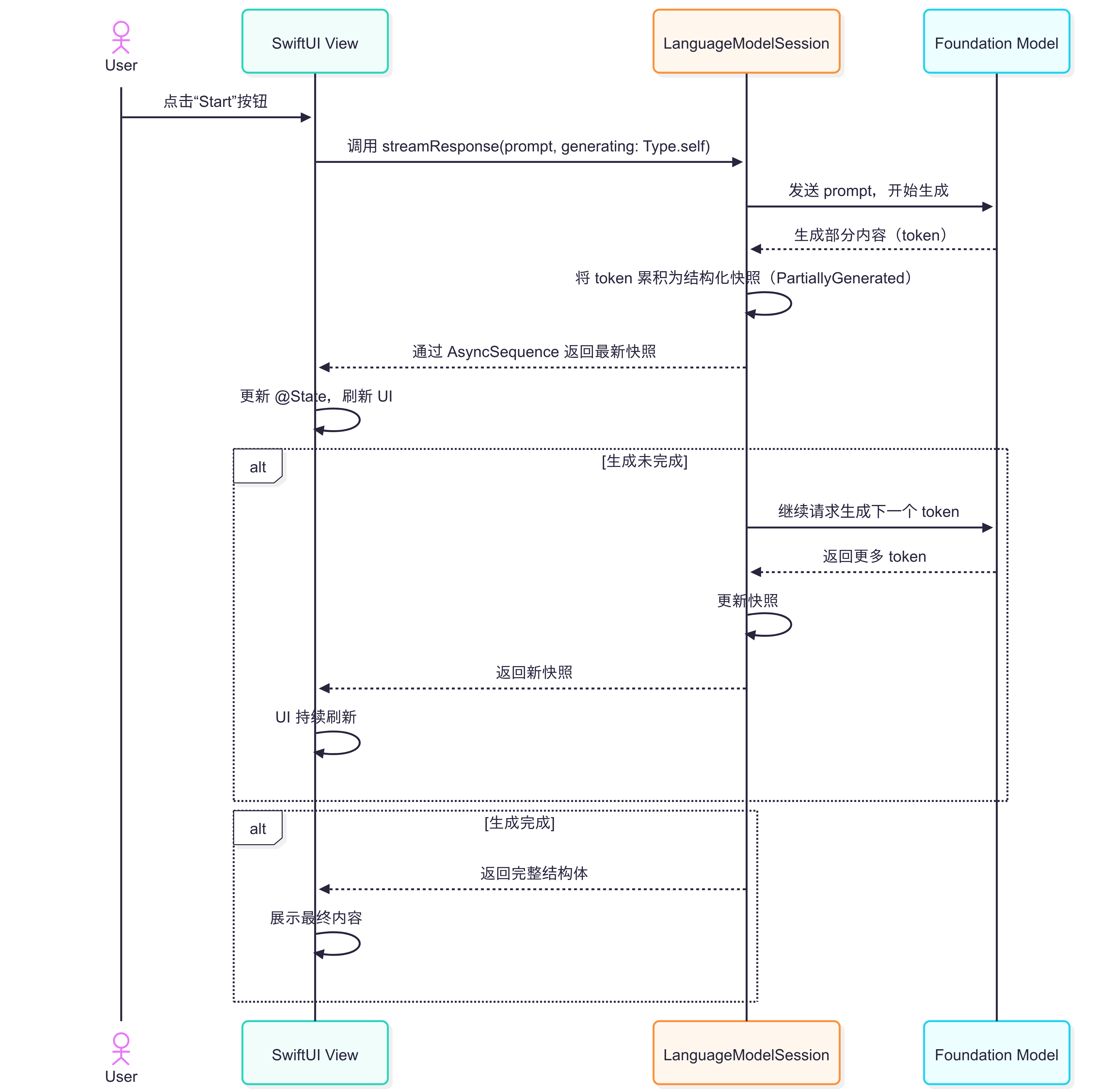
在 Foundation Model 中 开发者可以通过 session.streamResponse(to:) 启动生成模型的实时响应,模型会分批产出 token(部分文本),并让 UI 随之渲染,形成一句一句“边生成边展示”的交互体验。这种机制非常适合聊天机器人、行程规划、段落生成等需要即时反馈的场景。

相较于传统方式,大多数 LLM API 采用增量流式输出,即每次返回一小段 token,需要开发者手动拼接和解析。例如:
// 伪代码:传统 delta streaming
for delta in model.stream(prompt: "Hello") {
streamingText += delta
// 需要手动解析结构化内容
}这种方式在处理结构化数据时非常繁琐,尤其是需要在 UI 中实时展示部分结构化内容时,开发者不得不不断解析和修正中间状态,更加容易出错。
Foundation Models 框架引入了“快照流”(Snapshot Streaming)机制。其核心思想是:每次流式输出的不是原始 token 增量,而是“部分生成的结构体快照”。这些快照类型由 @Generable 宏自动生成,所有属性均为 Optional,随着模型生成进度逐步填充。
假设你有如下结构体:
@Generable
struct Itinerary {
var name: String
var days: [Day]
}@Generable 宏会自动生成一个 Itinerary.PartiallyGenerated 类型,其属性全部为 Optional
// 自动生成
struct PartiallyGenerated {
var name: String?
var days: [Day]?
}使用 session.streamResponse(to:) 方法即可获得一个异步序列,每次迭代返回最新的快照:
// Streaming partial generations
let stream = session.streamResponse(
to: "Craft a 3-day itinerary to Mt. Fuji.",
generating: Itinerary.self
)
for try await partial in stream {
print(partial)
}应用方式
这种快照流非常适合与 SwiftUI 等声明式 UI 框架结合。开发者可以将快照作为 @State 变量,随着流式生成自动刷新界面:
struct ItineraryView: View {
let session: LanguageModelSession
let dayCount: Int
let landmarkName: String
@State
private var itinerary: Itinerary.PartiallyGenerated?
var body: some View {
//...
Button("Start") {
Task {
do {
let prompt = """
Generate a (dayCount) itinerary \
to (landmarkName).
"""
let stream = session.streamResponse(
to: prompt,
generating: Itinerary.self
)
for try await partial in stream {
self.itinerary = partial
}
} catch {
print(error)
}
}
}
}
}具体来说,当用户点击按钮后,View 通过session.streamResponse(to:) 发起流式请求,模型逐步生成 token,session 将 token 累积为结构化快照,且每生成一部分,session 通过异步序列把最新快照传递给 View,而 View 触发 UI 实时刷新直到生成完成,View 展示最终内容。
结语
通过深入剖析 Apple Foundation Models 框架的设计与实现,我们可以看到苹果在 LLM 接入路径上选择了一条与 OpenAI、Anthropic 等厂商截然不同的路线:它并不急于堆叠参数量或模型大小,而是优先关注框架层的封装效率与开发者体验。无论是以 Swift 类型为核心的 Guided Generation、Tool Calling,还是面向用户交互优化的 Snapshot Streaming,都体现了 Apple 在“AI 原生平台”建设上的系统性思考。
对于开发者而言,这一套从语言级支持、UI 交互到本地执行完整链路的封装,极大地降低了 AI 能力的集成成本,也预示着应用形态将在未来发生深刻变革。尽管 Apple 的 Foundation Model 框架目前国行设备尚无法直接接入和使用,但这套LLM 交互体系依然为我们提供了极具价值的参考范本。作为中国的开发者,我们可以跳脱“如何使用”的局限,深入思考 Apple 在原生化集成、类型安全、功能组合等方面的设计思路,打造更加稳健、易用且贴近系统级体验的 AI 原生能力。
若你也对这一框架的技术细节感兴趣,推荐按照以下 session 顺序深入学习: