MusicGen 是 Meta 于2023年6月发布的开源音乐模型,我等待了20分钟在 Mac 上创作了一段简短的 Lo-Fi 音乐。在阅读文章之前,读者可以先试听一下这段音乐。
本文并不会从学术领域介绍模型,如果你对论文感兴趣可以移步 Simple and Controllable Music Generation。
前言
人工智能音乐创作的阶段演进可以具体分为以下几个阶段:
- 基于规则的阶段(Rule-Based): 上世纪五六十年代主要依赖预定的音乐规则和算法,包括早期的音乐生成软件,如MusiCog。
- 基于模型的阶段(Model-Based): 随着机器学习的兴起,音乐生成开始采用基于模型的方法,使用统计模型和学习算法,Magenta就采用了循环神经网络(RNN)来学习音乐的结构和风格。
- 深度学习阶段(Deep Learning): 近年来深度学习技术的发展推动了人工智能音乐创作的进一步发展。使用卷积神经网络(CNN)和长短时记忆网络(LSTM)等深度学习模型,使系统更好地理解音乐的层次结构和语境。
如果你对这个深度学习生成音乐议题感兴趣,可以移步DEEP LEARNING FOR MUSIC GENERATION,我比较感兴趣的的模型主要有deepjazz、MusicLM、MusicGen,后文中提到的人工智能生成音乐工具都会围绕MusicGen展开。
清单
- MusicLM:MusicLM是一个以文本为条件的音频生成模型,可以从文本描述中生成高保真的音乐。该模型采用层次化的序列到序列的方法,能够生成几分钟内一致的音乐。MusicLM使用三种模型来提取作为条件自回归音乐生成输入的音频表示,分别是SoundStream、w2v-BERT和MuLan。
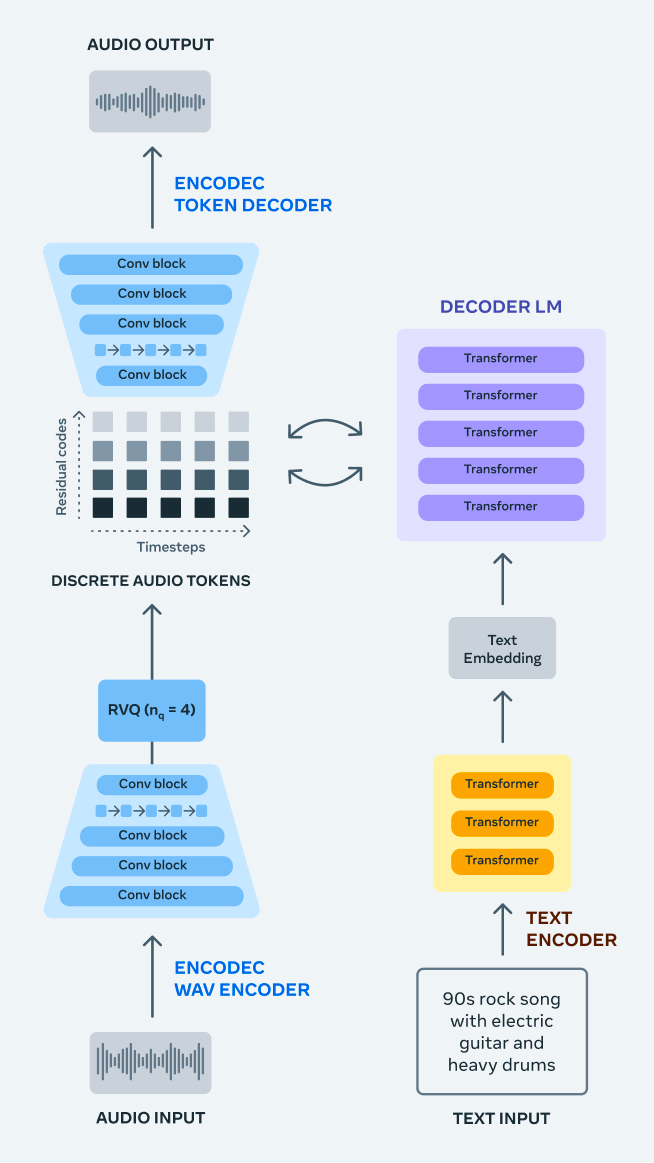
- MusicGen:MusicGen可以进行文字到音乐的生成,也可以根据提取的主旋律来进行旋律引导的音乐生成,它基于Transformer模型并采用Meta的 EnCodec 编译器将音频数据分解为小单元处理。接受了20000小时的音乐训练,使用了来自媒体内容服务商ShutterStock和Pond5的10000首“高质量”授权音乐和390000首纯音乐。
- AudioCraft:Meta发布的一款可以根据用户给出的文本提示创作音频和音乐的开源工具,可以称之为**“AI音乐生成领域的全家桶”**,它包括AudioGen、EnCodec(改进版)和MusicGen三个核心部件,流程上可以将用户给出的文本指令转变为任何类型的音频或者音乐,再由EnCodec(改进版)进行优化。
介绍
MusicLM 由Google在2023年1月发布,而 MusicGen 由Meta于2023年6月发布。
根据 Techcrunch 编辑 Kyle Wiggers的测评,两者表现不分伯仲,但 MusicGen 在与文本匹配度与作曲可信度上更胜一筹,并且 MusicGen 在使用方式上除了文本提示还可搭配音频一同作为生成音乐的条件。
MusicGen 在官方网站上提供了音乐片段的试听,并且在 HuggingFace 上提供了试玩。该开源的模型本身基于PyTorch,你可以通过这两个网页对这个模型有一个大概的了解。
- facebook/musicgen-melody — a music generation model capable of generating music condition on text and melody inputs. Note, you can also use text only.
- facebook/musicgen-small — a 300M transformer decoder conditioned on text only.
- facebook/musicgen-medium — a 1.5B transformer decoder conditioned on text only.
- facebook/musicgen-large — a 3.3B transformer decoder conditioned on text only.
- facebook/musicgen-melody-large — a 3.3B transformer decoder conditioned on and melody.
- facebook/musicgen-stereo-* same as the previous models but fine tuned to output stereo audio.
Meta 给出了这几个模型在 MusicCaps 数据集上的表现,有四个指标来衡量
| Model | Frechet Audio Distance | KLD | Text Consistency | Chroma Cosine Similarity |
|---|---|---|---|---|
| facebook/musicgen-small | 4.88 | 1.42 | 0.27 | - |
| facebook/musicgen-medium | 5.14 | 1.38 | 0.28 | - |
| facebook/musicgen-large | 5.48 | 1.37 | 0.28 | - |
| facebook/musicgen-melody | 4.93 | 1.41 | 0.27 | 0.44 |
在我冲浪的时候我发现了Youtube上的博主Tim Pearce展示的使用AI工具创作的五小时Lo-Fi音乐,就听感上来说和流媒体音乐平台听到的 Lo-Fi 非常接近了,从描述看他的创作流程大致包括了
- 使用 ChatGPT、Bing Chat 和 Bard 生成歌名
- 使用 MusicGen 生成音乐片段
- 使用 StableDiffusion 生成专辑封面
- 使用 CLAP 对歌名与歌曲描述进行匹配,排序移除低质量的音频
- 使用 CLIP 将歌名与图片进行匹配
 这为我们创作流水线音乐提供了重要思路。
这为我们创作流水线音乐提供了重要思路。
安装
AudioCraft 安装非常简单直接,你首先需要确保你的计算机上具备
- Python 3.9 (或更高版本,Mac上执行命令需要使用python3)
- pip (用于安装Pytorch)
- Pytorch 2.0.0 (或更高版本,官方文档使用2.1.0)
- ffmpeg (可以使用 apt-get 或 conda 进行安装,Mac上可以使用brew)
# 如果还没有安装Pytorch
python -m pip install 'torch==2.1.0'
# 在安装软件包之前运行这行代码
python -m pip install setuptools wheel
# 运行其中一行代码,分别对应了稳定版|实验版|clone 到本地进行训练
python -m pip install -U audiocraft
python -m pip install -U git+https://git@github.com/facebookresearch/audiocraft#egg=audiocraft
python -m pip install -e .
# 推荐安装ffmpeg
sudo apt-get install ffmpeg
# 在Mac上可以使用homebrew
brew install ffmpeg
# 如果使用 Anaconda 或 Miniconda
conda install "ffmpeg<5" -c conda-forgeAudioCraft 提供了 GUI 和 API 两种使用方式,如果你是初学者,建议直接用 GUI 体验音乐创作过程。
配置
GUI
当你安装好以上的软件包之后,在命令行中输入以下命令就可以立即开始你的音乐创作。
cd audiocraft
python -m demos.musicgen_app --shareAudioCraft 会启动服务让你能够在本机和远程访问GUI,如果顺利启动了,你会看到如下的提示:
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://{XXXXXXXXXXXXXX}.gradio.live直接用浏览器访问 http://127.0.0.1:7860 就可以访问。
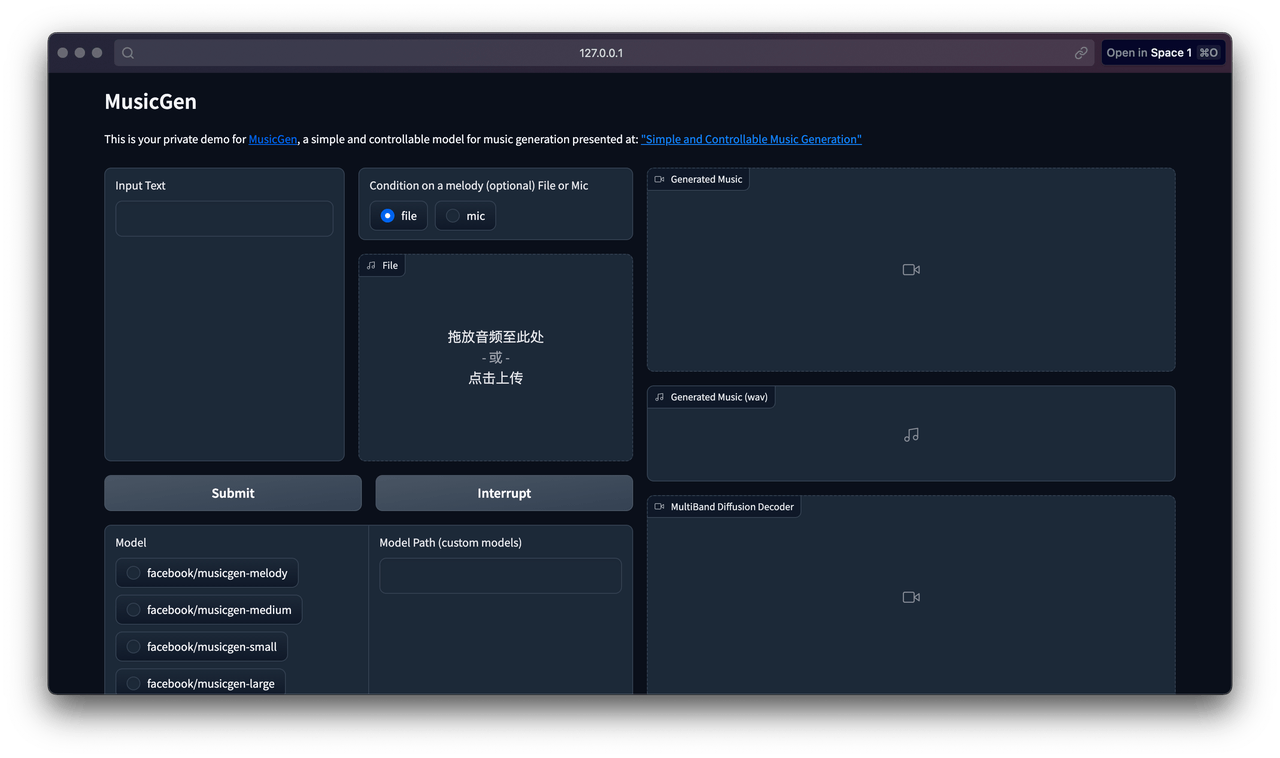
你可以直接在操作面板上选择模型、更改参数或者附加旋律文件。如果你希望尽快开始,只需输入你希望生成的音乐描述并点击“Submit”按钮,模型就会自动开始下载(取决于网络速度),并在一段时间内生成音乐文件。
API
如果你对 Jupyter NoteBook 比较了解,可以直接跳过这一部分,直接参考
../demos/musicgen_demo.ipynb这个文件.
AudioCraft 提供了简略的API文档,可以方便开发者执行一些下游任务。为了搞明白怎么把模型在命令行跑起来,你需要了解一些相关参数。
首先需要初始化 MusicGen,您可以从前文中选择一个模型快速开始,这里简化流程使用了facebook/musicgen-small这个模型。
from audiocraft.models import MusicGen
from audiocraft.models import MultiBandDiffusion
USE_DIFFUSION_DECODER = False
# Using small model, better results would be obtained with `medium` or `large`.
model = MusicGen.get_pretrained('facebook/musicgen-small')
if USE_DIFFUSION_DECODER:
mbd = MultiBandDiffusion.get_mbd_musicgen()
model.set_generation_params(
use_sampling=True,
top_k=250,
duration=30
)AudioCraft 包含了一些可配置的生成参数,你可以了解一下每个参数的用途,也可以直接使用默认值。
use_sampling(bool, optional): use sampling if True, else do argmax decoding. Defaults to True.top_k(int, optional): top_k used for sampling. Defaults to 250.top_p(float, optional): top_p used for sampling, when set to 0 top_k is used. Defaults to 0.0.temperature(float, optional): softmax temperature parameter. Defaults to 1.0.duration(float, optional): duration of the generated waveform. Defaults to 30.0.cfg_coef(float, optional): coefficient used for classifier free guidance. Defaults to 3.0.
官方给出的 Demo 按照下游任务进行了区分,分别是音乐续作、文本生成音乐以及旋律生成音乐。
音乐续作
音乐续作需要用到的能力是generate_continuation,官方的 Demo 使用这个函数来生成一个包含”bip bip”声音的序列,并使用这个序列给定相应的参数来生成音频。
def generate_continuation(self, prompt: torch.Tensor, prompt_sample_rate: int,
descriptions: tp.Optional[tp.List[tp.Optional[str]]] = None,
progress: bool = False, return_tokens: bool = False) \
-> tp.Union[torch.Tensor, tp.Tuple[torch.Tensor, torch.Tensor]]:
"""Generate samples conditioned on audio prompts.
Args:
prompt (torch.Tensor): A batch of waveforms used for continuation.
Prompt should be [B, C, T], or [C, T] if only one sample is generated.
prompt_sample_rate (int): Sampling rate of the given audio waveforms.
descriptions (list of str, optional): A list of strings used as text conditioning. Defaults to None.
progress (bool, optional): Flag to display progress of the generation process. Defaults to False.
"""以下get_bip_bip函数能够生成一系列以给定频率播放的”bip bip”声(“bip bip”声是一种常见的电子音乐声音效果,通常由电子合成器生成),其中函数的参数包括:
bip_duration: 表示”bip bip bip”声的持续时间,单位为秒,默认值为0.125秒。frequency: 表示”bip bip bip”声的频率,默认值为440赫兹。duration: 表示生成的音频文件的总时长,单位为秒,默认值为0.5秒。sample_rate: 表示音频文件的采样率,单位为千赫兹,默认值为32000千赫兹。device: 表示计算设备,默认为”cuda”,如果使用Mac需要更改为”cpu”。
import math
import torchaudio
import torch
from audiocraft.utils.notebook import display_audio
def get_bip_bip(bip_duration=0.125, frequency=440,
duration=0.5, sample_rate=32000, device="cuda"):
t = torch.arange(
int(duration * sample_rate), device="cuda", dtype=torch.float) / sample_rate
wav = torch.cos(2 * math.pi * 440 * t)[None]
tp = (t % (2 * bip_duration)) / (2 * bip_duration)
envelope = (tp >= 0.5).float()
return wav * envelope
# 使用合成信号来提示生成音频的音调和BPM。
res = model.generate_continuation(
get_bip_bip(0.125).expand(2, -1, -1),
32000, ['Jazz jazz and only jazz',
'Heartful EDM with beautiful synths and chords'],
progress=True)
display_audio(res, 32000)progress=True表示在生成音频的过程中显示进度,传递给generate_continuation方法的descriptions包含两个部分,最后使用 display_audio 函数来显示这个音频,对应的生成结果可以在下面试听。
仓库的assets文件夹下给出了一些可用的音频,当然你也可以用自己的音频,如果音频太长请务必提前修剪。
prompt_waveform, prompt_sr = torchaudio.load("../assets/bach.mp3")
prompt_duration = 2
prompt_waveform = prompt_waveform[..., :int(prompt_duration * prompt_sr)]
output = model.generate_continuation(prompt_waveform, prompt_sample_rate=prompt_sr, progress=True, return_tokens=True)
display_audio(output[0], sample_rate=32000)
if USE_DIFFUSION_DECODER:
out_diffusion = mbd.tokens_to_wav(output[1])
display_audio(out_diffusion, sample_rate=32000)文本条件生成
如果你只想要简单的用文本生成音乐,你需要关心的只有generate这个方法。
def generate(self, descriptions: tp.List[str], progress: bool = False, return_tokens: bool = False) \
-> tp.Union[torch.Tensor, tp.Tuple[torch.Tensor, torch.Tensor]]:
"""Generate samples conditioned on text.
Args:
descriptions (list of str): A list of strings used as text conditioning.
progress (bool, optional): Flag to display progress of the generation process. Defaults to False.
"""相较于音乐续作,文本条件生成音乐需要关注的参数更少,可以尝试用不同的descriptions生成不同风格的音乐,这也是 AIGC 的乐趣所在。
from audiocraft.utils.notebook import display_audio
output = model.generate(
descriptions=[
#'80s pop track with bassy drums and synth',
#'90s rock song with loud guitars and heavy drums',
#'Progressive rock drum and bass solo',
#'Punk Rock song with loud drum and power guitar',
#'Bluesy guitar instrumental with soulful licks and a driving rhythm section',
#'Jazz Funk song with slap bass and powerful saxophone',
'drum and bass beat with intense percussions'
],
progress=True, return_tokens=True
)
display_audio(output[0], sample_rate=32000)
if USE_DIFFUSION_DECODER:
out_diffusion = mbd.tokens_to_wav(output[1])
display_audio(out_diffusion, sample_rate=32000)旋律条件生成
如果需要使用旋律条件生成音乐,需要使用facebook/musicgen-melody相关的模型。
def generate_with_chroma(self, descriptions: tp.List[str], melody_wavs: MelodyType,
melody_sample_rate: int, progress: bool = False,
return_tokens: bool = False) -> tp.Union[torch.Tensor,
tp.Tuple[torch.Tensor, torch.Tensor]]:
"""Generate samples conditioned on text and melody.
Args:
descriptions (list of str): A list of strings used as text conditioning.
melody_wavs: (torch.Tensor or list of Tensor): A batch of waveforms used as
melody conditioning. Should have shape [B, C, T] with B matching the description length,
C=1 or 2. It can be [C, T] if there is a single description. It can also be
a list of [C, T] tensors.
melody_sample_rate: (int): Sample rate of the melody waveforms.
progress (bool, optional): Flag to display progress of the generation process. Defaults to False.
"""Demo 代码设置了模型的生成参数,将音乐的持续时间设置为8秒。运行后将从./assets/bach.mp3文件加载音频数据并将其转换为模型可以处理的格式,之后结合参数使用模型生成音乐,笔者同样将产物粘贴于此。
import torchaudio
from audiocraft.utils.notebook import display_audio
model = MusicGen.get_pretrained('facebook/musicgen-melody')
model.set_generation_params(duration=8)
melody_waveform, sr = torchaudio.load("../assets/bach.mp3")
melody_waveform = melody_waveform.unsqueeze(0).repeat(2, 1, 1)
output = model.generate_with_chroma(
descriptions=[
'80s pop track with bassy drums and synth',
'90s rock song with loud guitars and heavy drums',
],
melody_wavs=melody_waveform,
melody_sample_rate=sr,
progress=True, return_tokens=True
)
display_audio(output[0], sample_rate=32000)
if USE_DIFFUSION_DECODER:
out_diffusion = mbd.tokens_to_wav(output[1])
display_audio(out_diffusion, sample_rate=32000)FAQ
- 如果你使用的是基于ARM芯片的Mac,在运行过程上遇到了问题,请尝试修改
device代码。
MODEL = MusicGen.get_pretrained({model}, device='cpu')- Mac生成音乐的耗时很长,推荐接入高性能的计算资源,Meta 给出的建议是 16G的显存。
- 如果你希望生成更长长度的音频,请尝试修改以下代码中
maximum的数值。
with gr.Row():
duration = gr.Slider(minimum=1, maximum=120, value=10, label="Duration", interactive=True)- MusicGen 暂时还不能用中文作为输入,如果你希望获得更多生成音乐的 prompt 可以让ChatGPT为你做这件事,例如“假设你是一个熟悉 MusicGen 模型的prompt大师,现在需要使用 MusicGen 模型生成一些 Lo-Fi 音乐,风格类似于Lo-Fi girl提供的那些音乐,请尝试用英语给出十条优质的prompt”
"Generate a Lo-Fi music snippet with a gentle electric piano and soft drum beats, creating a warm and relaxed atmosphere."
"Produce a Lo-Fi music piece emphasizing soothing guitar and natural ambient sounds, evoking a sense of tranquility and comfort."
"Compose a Lo-Fi music track using smooth synthesizers and soft percussion, aiming for a relaxed and pleasant vibe."
"Craft a Lo-Fi music snippet with a flowing melody, incorporating gentle drum beats and subtle vocal nuances for a dreamy atmosphere."
"Generate Lo-Fi music by blending warm piano tones with light, lively drum beats, offering both tranquility and a touch of vitality."
"Build a Lo-Fi music piece using deep bass tones and mellow synth sounds, creating an immersive and meditative experience."
"Create Lo-Fi music with a slow tempo and serene melody, providing a sense of relaxation and meditation."
"Use soft piano tones and airy synthesizers to produce a Lo-Fi music track, capturing the feeling of strolling through a peaceful summer afternoon."
"Generate Lo-Fi music with a combination of slow rhythms, mellow guitar, and subtle electronic effects, establishing a relaxed and joyful atmosphere."
"Compose a Lo-Fi music piece featuring melodic strings and warm synthesizers, infusing a hint of romance and tranquility."应用
AI生成音乐的前景是无穷的,如果算力能够达到要求让生成音乐的时间短于音乐播放的时间,这样生成的音乐就一直是不同的、连贯的,同时可以想象的落地的场景也很多,例如
- 生成游戏与视频背景配乐,定制个性化背景音乐,减少版税风险
- 生成特定场景的音乐,例如工作、学习、驾驶、放松或睡眠
- 启发音乐创作者的旋律创作与编曲灵感,生成可选的、改进的伴奏
试想你开了一家程序员咖啡店搭建了一整套创作流水线,只需要在输入框输入prompt“适合咖啡店播放的Jazz音乐”,抑或在下雨天可以键入“适合雨天播放的慢节奏爵士乐”,你的计算设备就能够为你输出永不间断且几乎永不重复的音乐,你甚至不需要为音乐支付版权费用。
后记
目前 MusicGen 的应用还仅限于研究领域,如果在未来投入商业领域还有诸多问题亟待解决,例如
- 训练 AudioCraft 的数据集缺乏多样性,素材大多为西式音乐,缺少东方音乐的元素
- 无法生成真实的人声且效果不完全可控
- 有时生成的音乐甚至让人感觉不适
- 有时会生成歌曲结尾后直接静音
- prompt语言仅限于英语,不能像ChatGPT一样具有普适性
- 音乐生成的质量与节奏感与作曲家作品仍然存在一定差距
但无疑,MusicGen 可以成为一个得力的工具。在编程领域我们提出结对编程这个概念,在音乐创作领域是否会有更多结对谱曲的出现呢,让我们拭目以待。