实验简介
关联规则表示不同数据项目在同一事件中出现的相关性,下图中超市市场分析员分析顾客购买商品的场景可以直观地理解关联规则。

顾客购买面包同时也购买牛奶的购物模式可以用以下关联规则表示:
面包 => 牛奶 [ 支持度 =2%, 置信度 =60%]其中面包是规则前项(Antecedent),牛奶是规则后项 (Consequent)。实例数(Instances)表示所有购买记录中包含面包的记录的数量。支持度(Support)表示购买面包的记录数占所有购买记录数的百分比。规则支持度(Rule Support)表示同时购买面包和牛奶的记录数占所有的购买记录数的百分比。置信度(confidence)表示同时购买面包和牛奶的记录数占购买面包记录数的百分比。提升(Lift)表示置信度与已知购买牛奶的百分比的比值,提升大于 1 的规则才是有意义的。 如果关联满足最小支持度阈值和最小置信度阈值就可以认为关联规则是有意义的。这些阈值由用户或领域专家设定。就顾客购物而言,根据以往的购买记录,找出满足最小支持度阈值和最小置信度阈值的关联规则,就找到顾客经常同时购买的商品。
Apriori
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。 本次实验中有如下步骤:
- 使用 WEKA 的 Apriori 策略对数据集进行关联操作
- 查看并分析关联结果
- 分析 Apriori 的算法与特征
FPgrowth
Apriori算法在产生频繁模式完全集前需要对数据库进行多次扫描,同时产生大量的候选频繁集,这就使Apriori算法时间和空间复杂度较大。 FP-Growth算法针对Apriori算法在挖掘长频繁模式时性能低下的特点提出了改进,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息。FP-Growth算法使用了一种称为频繁模式树(Frequent Pattern Tree)的数据结构,FP-tree是一种特殊的前缀树,由频繁项头表和项前缀树构成。FP-Growth算法基于以上的结构加快整个挖掘过程。 实验包含如下步骤:
- 使用 WEKA 的FPgrowth 策略对数据集进行关联操作
-
查看并分析关联结果 -
对比分析 FPgrowth 策略与 Apriori 策略的效果
实验数据
本次实验的数据我参照Waikato大学的数据挖掘教程,选择了vote.arff 数据集,这是一个关于1984年美国国会投票记录数据集,其中包含投票者的身份(民主党人或共和党人)以及多项议题的投票结果,如下图所示:

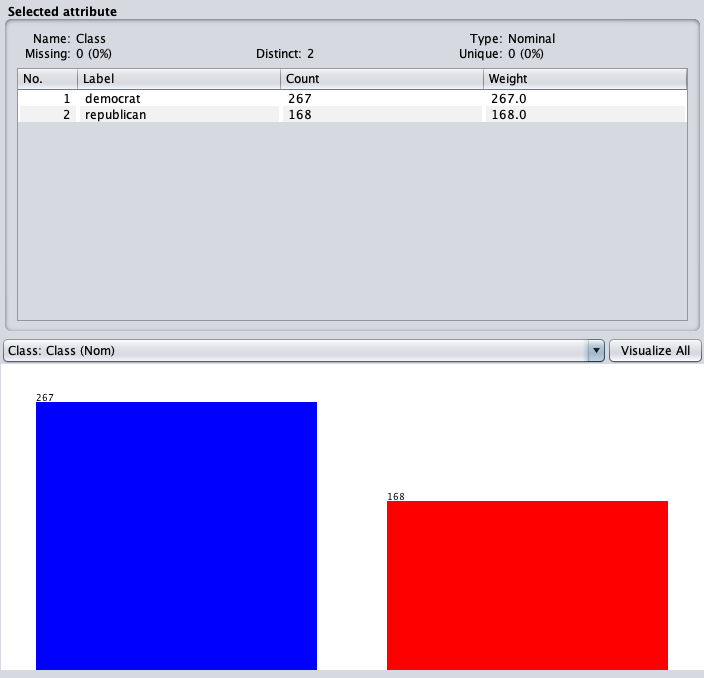 这个数据集包含435条实例(投票信息),其中包含 267 位民主党人投票信息, 168 位共和党人投票信息。投票结果中有移民(immigration)、教育开支(education-spending)、、免税出口(duty-free-exports)等共16个议题。议员对于议题的表决不仅仅只用简单的“Y”、“N”标记,需要注意的是,被标记为“?”的数据并不是代表数据的缺失,可能代表议员持保留意见没有表决,部分数据集摘录如下:
这个数据集包含435条实例(投票信息),其中包含 267 位民主党人投票信息, 168 位共和党人投票信息。投票结果中有移民(immigration)、教育开支(education-spending)、、免税出口(duty-free-exports)等共16个议题。议员对于议题的表决不仅仅只用简单的“Y”、“N”标记,需要注意的是,被标记为“?”的数据并不是代表数据的缺失,可能代表议员持保留意见没有表决,部分数据集摘录如下:

由于数据集经过实验验证,数据已完成去噪声处理,并且数据中的“?”并非代表数据缺失,前文交代了相关意义,故不复进行数据预处理的步骤。
算法简介
Apriori
Apriori算法的主要思想为:首先找出所有频繁性至少和预定义的最小支持度一样的频繁项集,由频繁项集产生满足最小支持度和最小可信度的强关联规则,然后使用频繁项集产生期望的规则,产生只包含集合的项的所有规则,每一条规则的右部只有一项。一旦这些规则生成,那么只有那些大于用户给定的最小可信度的规则才被保留。 Apriori算法利用了“任一频繁项集的所有非空子集必须是频繁的”这一个性质。举例说,如果 {0, 1} 是频繁的,那么 {0}, {1} 也是频繁的,将条件倒置,可得“如果一个项集是非频繁项集,那么它的所有超集也是非频繁项集”这一结论。在算法流程中,首先需要找出频繁1-项集,记为L1;然后用L1来产生候选项集C2,对C2中的项进行判定挖掘产生L2,即频繁2-项集;如此循环往复直至无法发现更多的频繁k-项集。 由于Apriori算法每挖掘一层Lk就需要扫描整个数据库一遍,会产生大量的候选频繁集,使得Apriori算法时间和空间复杂度较大,以下为简单的算法示意图。

FP-Growth
FP-Growth算法针对Apriori算法在挖掘时可能出现的性能低下问题提出了改进,无论多少数据,只需要扫描两次数据集,提高了算法运行的效率。FP-Growth算法提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息,基于频繁模式树加快整个挖掘过程。 FP-Growth算法思路即不断迭代FP-tree的构造和投影过程,其算法过程大致如下:
- 扫描数据集一次,找到频繁1-项集(单项模式)
- 按频率降序对频繁项排序
- 再次扫描数据集,按F-list的逆序构造条件FP树
- 按F-list的逆序构造条件FP树,生成频繁项目集
实验过程
Apriori
使用WEKA进行Apriori相关性分析,其生成结果如下所示,WEKA默认显示十条最佳item sets结果。
Apriori
=======
Minimum support: 0.45 (196 instances)
Minimum metric <confidence>: 0.9
Number of cycles performed: 11
Generated sets of large itemsets:
Size of set of large itemsets L(1): 20
Size of set of large itemsets L(2): 17
Size of set of large itemsets L(3): 6
Size of set of large itemsets L(4): 1
Best rules found:
1. adoption-of-the-budget-resolution=y physician-fee-freeze=n 219 ==> Class=democrat 219 <conf:(1)> lift:(1.63) lev:(0.19) [84] conv:(84.58)
2. adoption-of-the-budget-resolution=y physician-fee-freeze=n aid-to-nicaraguan-contras=y 198 ==> Class=democrat 198 <conf:(1)> lift:(1.63) lev:(0.18) [76] conv:(76.47)
3. physician-fee-freeze=n aid-to-nicaraguan-contras=y 211 ==> Class=democrat 210 <conf:(1)> lift:(1.62) lev:(0.19) [80] conv:(40.74)
4. physician-fee-freeze=n education-spending=n 202 ==> Class=democrat 201 <conf:(1)> lift:(1.62) lev:(0.18) [77] conv:(39.01)
5. physician-fee-freeze=n 247 ==> Class=democrat 245 <conf:(0.99)> lift:(1.62) lev:(0.21) [93] conv:(31.8)
6. el-salvador-aid=n Class=democrat 200 ==> aid-to-nicaraguan-contras=y 197 <conf:(0.98)> lift:(1.77) lev:(0.2) [85] conv:(22.18)
7. el-salvador-aid=n 208 ==> aid-to-nicaraguan-contras=y 204 <conf:(0.98)> lift:(1.76) lev:(0.2) [88] conv:(18.46)
8. adoption-of-the-budget-resolution=y aid-to-nicaraguan-contras=y Class=democrat 203 ==> physician-fee-freeze=n 198 <conf:(0.98)> lift:(1.72) lev:(0.19) [82] conv:(14.62)
9. el-salvador-aid=n aid-to-nicaraguan-contras=y 204 ==> Class=democrat 197 <conf:(0.97)> lift:(1.57) lev:(0.17) [71] conv:(9.85)
10. aid-to-nicaraguan-contras=y Class=democrat 218 ==> physician-fee-freeze=n 210 <conf:(0.96)> lift:(1.7) lev:(0.2) [86] conv:(10.47)由于对类进行关联分析,故度量类型为置信度,将最小支持度下界(lowerBoundMinSupport)设置为0.1,迭代递减单位(delta)设置为0.05,度量最小值(minMetric)保持默认值0.9,WEKA会重复运行Apriori 算法几次,从最小支持度上界(upperBoundMinSupport)开始,以delta为单位进行迭代运算,当迭代次数达到设定的numRules数值时,或数值达到最小支持度下界(lowerBoundMinSupport)时停止迭代操作。 当前获取结果可以看出,最小支持度为0.45,包含196个实例,其中最小置信度为0.9,整个循环操作进行了11次,生成的频繁1-项集包含20个实例,频繁2-项集包含17个实例,频繁3-项集包含6个实例,而频繁4-项集只包含1个实例。 关联挖掘结果中最好的Rule得到了219条数据的确认,简要查看一下这条数据代表的意义,若一个议员为收养开支预算投赞成票、为冻结医师的费用投反对票,那么他很可能是民主党人。这是一条很有意思的信息,得到这样的信息也就是关联规则算法的意义所在。 评定Ranking Rules的方式不止有Confidence,还有Lift,Leverage和Conviction等,结果中对于每一个Rules也分别给出了各个排序规则的结果,如刚才列举的规则置信度达到了1,Lift值达到了1.63,Leverage值达到了0.19,等等,由于本次关联主要对类进行操作,由置信度的结果我们可以推断出这一规则可信度价值较高。
FPgrowth
使用WEKA进行FPgrowth相关性分析,将参数保持与Apriori相关性分析时不变,可见的效果是生成结果的时间缩短了不少,其生成结果如下图所示。
=== Associator model (full training set) ===
FPGrowth found 41 rules (displaying top 10)
1. [el-salvador-aid=y, Class=republican]: 157 ==> [physician-fee-freeze=y]: 156 <conf:(0.99)> lift:(2.44) lev:(0.21) conv:(46.56)
2. [crime=y, Class=republican]: 158 ==> [physician-fee-freeze=y]: 155 <conf:(0.98)> lift:(2.41) lev:(0.21) conv:(23.43)
3. [religious-groups-in-schools=y, physician-fee-freeze=y]: 160 ==> [el-salvador-aid=y]: 156 <conf:(0.97)> lift:(2) lev:(0.18) conv:(16.4)
4. [Class=republican]: 168 ==> [physician-fee-freeze=y]: 163 <conf:(0.97)> lift:(2.38) lev:(0.22) conv:(16.61)
5. [adoption-of-the-budget-resolution=y, anti-satellite-test-ban=y, mx-missile=y]: 161 ==> [aid-to-nicaraguan-contras=y]: 155 <conf:(0.96)> lift:(1.73) lev:(0.15) conv:(10.2)
6. [physician-fee-freeze=y, Class=republican]: 163 ==> [el-salvador-aid=y]: 156 <conf:(0.96)> lift:(1.96) lev:(0.18) conv:(10.45)
7. [religious-groups-in-schools=y, el-salvador-aid=y, superfund-right-to-sue=y]: 160 ==> [crime=y]: 153 <conf:(0.96)> lift:(1.68) lev:(0.14) conv:(8.6)
8. [el-salvador-aid=y, superfund-right-to-sue=y]: 170 ==> [crime=y]: 162 <conf:(0.95)> lift:(1.67) lev:(0.15) conv:(8.12)
9. [crime=y, physician-fee-freeze=y]: 168 ==> [el-salvador-aid=y]: 160 <conf:(0.95)> lift:(1.95) lev:(0.18) conv:(9.57)
10. [el-salvador-aid=y, physician-fee-freeze=y]: 168 ==> [crime=y]: 160 <conf:(0.95)> lift:(1.67) lev:(0.15) conv:(8.02)WEKA中给予FPgrowth的描述是:实现FP-growth算法的类,用于查找大型项集而无需生成候选项。由于WEKA中的FPgrowth机制,无法实现对class进行关联分析(我没有找到相关选项),所以我使用FPgrowth得到的关联结果与之前Apriori关联分析的结果不同。 得到的置信度最高的规则代表着如果医院对萨尔瓦多议题投了赞成票并且他的身份是共和党人,那么大概率他会给冻结医师的费用投赞成票,支持该Rule的记录存在156条,置信度达到了0.99,Lift值达到了2.44。 至于计算的复杂度问题,运行过程花费的时间也可以预见一些结果,通过查资料得到一般性结论:Apriori算法的效率最低,因为需要很多次的扫描数据库;其次FP—Growth算法在长事物数据上表现很差,因为当事物很长时树的深度也很大,需要求解的子问题就变得特别多,因此效率会迅速下降。
参考资料
Sample Weka Data Sets 应用关联规则模型提高超市销量-IBM Association Rule Mining Algorithms 频繁模式挖掘中Apriori、FP-Growth和Eclat算法的实现和对比